
Recently
Rob and I visited
Soile and
Lars. We had a lovely
time wandering around Helsinki with them, and I also spent a good chunk of time
with Lars working on some design and planning for the
Yarn test specification and tooling.
You see, I wrote a
Rust implementation of Yarn
called
rsyarn "for fun" and in doing
so I noted a bunch of missing bits in the understanding Lars and I shared about
how Yarn should work. Lars and I filled, and re-filled, a whiteboard with
discussion about what the 'Yarn specification' should be, about various
language extensions and changes, and also about what functionality a normative
implementation of Yarn should have.
This article is meant to be a write-up of all of that discussion, but before I
start on that, I should probably summarise what Yarn is.
Yarn is a mechanism for specifying tests in a form which is more like
documentation than code. Yarn follows the concept of
BDD story based
design/testing and has a very
Cucumberish scenario
language in which to write tests. Yarn takes, as input,
Markdown documents which contain code
blocks with Yarn tests in them; and it then runs those tests and reports on the
scenario failures/successes.
As an example of a poorly written but still fairly effective Yarn suite, you
could look at
Gitano's tests or perhaps
at
Obnam's tests
(
rendered as HTML). Yarn is not trying
to replace unit testing, nor other forms of testing, but rather seeks to be one
of a suite of test tools used to help validate software and to verify
integrations. Lars writes Yarns which
test his server setups for example.
As an example, lets look at what a simple test might be for the behaviour of
the
/bin/true tool:
SCENARIO true should exit with code zero
WHEN /bin/true is run with no arguments
THEN the exit code is 0
AND stdout is empty
AND stderr is empty
Anyone ought to be able to understand exactly what that test is doing, even
though there's no obvious code to run. Yarn statements are meant to be easily
grokked by both developers and managers. This should be so that managers can
understand the tests which verify that requirements are being met, without
needing to grok python, shell, C, or whatever else is needed to implement the
test where the Yarns meet the metal.
Obviously, there needs to be a way to join the dots, and Yarn calls those
things
IMPLEMENTS, for example:
IMPLEMENTS WHEN (\S+) is run with no arguments
set +e
"$ MATCH_1 " > "$ DATADIR /stdout" 2> "$ DATADIR /stderr"
echo $? > "$ DATADIR /exitcode"
As you can see from the example, Yarn
IMPLEMENTS can use regular expressions
to capture parts of their invocation, allowing the test implementer to handle
many different scenario statements with one implementation block. For the rest
of the implementation, whatever you assume about things will probably be okay
for now.
Given all of the above, we (Lars and I) decided that it would make a lot of
sense if there was a set of Yarn scenarios which could validate a Yarn
implementation. Such a document could also form the basis of a Yarn
specification and also a manual for writing reasonable Yarn scenarios. As
such, we wrote up a three-column approach to what we'd need in that test suite.
Firstly we considered what the core features of the Yarn language are:
- Scenario statements themselves (
SCENARIO, GIVEN, WHEN, THEN,
ASSUMING, FINALLY, AND, IMPLEMENTS, EXAMPLE, ...)
- Whitespace normalisation of statements
- Regexp language and behaviour
IMPLEMENTS current directory, data directory, home directory, and also
environment.- Error handling for the statements, or for missing
IMPLEMENTS
- File (and filename) encoding
- Labelled code blocks (since commonmark includes the backtick code block
kind)
- Exactly one
IMPLEMENTS per statement
We considered unusual (or corner) cases and which of them needed defining in
the short to medium term:
- Statements before any SCENARIO or IMPLEMENTS
- Meaning of split code blocks (concatenation?)
- Meaning of code blocks not at the top level of a file (ignore?)
- Meaning of HTML style comments in markdown files
- Odd scenario ordering (e.g.
ASSUMING at the end, or FINALLY at the
start)
- Meaning of empty lines in code blocks or between them.
All of this comes down to how to interpret input to a Yarn implementation. In
addition there were a number of things we felt any "normative" Yarn
implementation would have to handle or provide in order to be considered
useful. It's worth noting that we don't specify anything about an
implementation being a command line tool though...
- Interpreter for
IMPLEMENTS (and arguments for them)
- "Library" for those implementations
- Ability to require that failed
ASSUMING statements lead to an error
- A way to 'stop on first failure'
- A way to select a specific scenario to run, from a large suite.
- Generation of timing reports (per scenario and also per statement)
- A way to 'skip' missing
IMPLEMENTS
- A clear way to identify the failing step in a scenario.
- Able to treat multiple input files as a single suite.
There's bound to be more, but right now with the above, we believe we have two
roughly conformant Yarn implementations. Lars' Python based implementation
which lives in
cmdtest (and which I shall refer to as
pyyarn for now) and
my Rust based one (
rsyarn).
One thing which
rsyarn supports, but
pyyarn does not, is running multiple
scenarios in parallel. However when I wrote that support into
rsyarn I
noticed that there were plenty of issues with running stuff in parallel. (A
problem I'm sure any of you who know about threads will appreciate).
One particular issue was that scenarios often need to share resources which
are not easily sandboxed into the
$ DATADIR provided by Yarn. For example
databases or access to limited online services. Lars and I had a good chat
about that, and decided that a reasonable language extension could be:
USING database foo
with its counterpart
RESOURCE database (\S+)
LABEL database-$1
GIVEN a database called $1
FINALLY database $1 is torn down
The
USING statement should be reasonably clear in its pairing to a
RESOURCE
statement. The
LABEL statement I'll get to in a moment (though it's only
relevant in a
RESOURCE block, and the rest of the statements are essentially
substituted into the calling scenario at the point of the
USING.
This is nowhere near ready to consider adding to the specification though.
Both Lars and I are uncomfortable with the
$1 syntax though we can't think of
anything nicer right now; and the
USING/
RESOURCE/
LABEL vocabulary isn't
set in stone either.
The idea of the
LABEL is that we'd also require that a normative Yarn
implementation be capable of specifying resource limits by name. E.g. if a
RESOURCE used a
LABEL foo then the caller of a Yarn scenario suite could
specify that there were 5
foos available. The Yarn implementation would then
schedule a maximum of 5 scenarios which are using that label to happen
simultaneously. At bare minimum it'd gate new users, but at best it would
intelligently schedule them.
In addition, since this introduces the concept of parallelism into Yarn proper,
we also wanted to add a maximum parallelism setting to the Yarn implementation
requirements; and to specify that any resource label which was not explicitly
set had a usage limit of 1.
Once we'd discussed the parallelism, we decided that once we had a nice syntax
for expanding these sets of statements anyway, we may as well have a syntax for
specifying scenario language expansions which could be used to provide
something akin to macros for Yarn scenarios. What we came up with as a
starter-for-ten was:
CALLING write foo
paired with
EXPANDING write (\S+)
GIVEN bar
WHEN $1 is written to
THEN success was had by all
Again, the
CALLING/
EXPANDING keywords are not fixed yet, nor is the
$1
type syntax, though whatever is used here should match the other places where
we might want it.
Finally we discussed multi-line inputs in Yarn. We currently have a syntax
akin to:
GIVEN foo
... bar
... baz
which is directly equivalent to:
GIVEN foo bar baz
and this is achieved by collapsing the multiple lines and using the whitespace
normalisation functionality of Yarn to replace all whitespace sequences with
single space characters. However this means that, for example, injecting
chunks of
YAML into a Yarn scenario is a pain, as would be including any
amount of another whitespace-sensitive input language.
After a lot of to-ing and fro-ing, we decided that the right thing to do would
be to redefine the
... Yarn statement to be whitespace preserving and to then
pass that whitespace through to be matched by the
IMPLEMENTS or whatever. In
order for that to work, the regexp matching would have to be defined to treat
the input as a single line, allowing
. to match
\n etc.
Of course, this would mean that the old functionality wouldn't be possible, so
we considered allowing a
\ at the end of a line to provide the current kind
of behaviour, rewriting the above example as:
GIVEN foo \
bar \
baz
It's not as nice, but since we couldn't find any real uses of
... in any of
our Yarn suites where having the whitespace preserved would be an issue, we
decided it was worth the pain.
None of the above is, as of yet, set in stone. This blog posting is about me
recording the information so that it can be referred to; and also to hopefully
spark a little bit of discussion about Yarn. We'd welcome emails to our usual
addresses, being poked on Twitter, or on IRC in the common spots we can be
found. If you're honestly unsure of how to get hold of us, just comment on
this blog post and I'll find your message eventually.
Hopefully soon we can start writing that Yarn suite which can be used to
validate the behaviour of
pyyarn and
rsyarn and from there we can implement
our new proposals for extending Yarn to be even more useful.
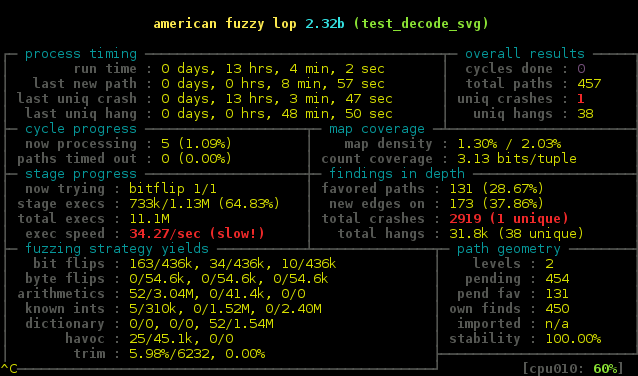


 Every now and again I get this problem where Firefox won t render text correctly (on a Debian/stretch system). Most websites are fine, but the odd site just shows up with blanks where the text should be. Initially I thought it was
Every now and again I get this problem where Firefox won t render text correctly (on a Debian/stretch system). Most websites are fine, but the odd site just shows up with blanks where the text should be. Initially I thought it was 




























{kind=link}